Elasticsearch 备份迁移
备份原理
备份说明
使用无论哪个存储数据的软件,定期备份数据都是很重要的;Elasticsearch 集群副本提供了高可靠性,可以容忍零星的节点丢失而不会中断服务
但是,集群副本并不提供对灾难性故障的保护;对于这种情况,我们需要的是对集群真正的备份灾难发生后有一个可靠的备份来还原数据
本文将描述如何使用官方提供的 Snapshot API 备份恢复 Elasticsearch 数据:Snapshot & Restore;文档中关于增量快照进行了说明:
你的第一个快照会是一个数据的完整拷贝,但是所有后续的快照会保留的是已存快照和新数据之间的差异。随着你不时的对数据进行快照,备份也在增量的添加和删除。这意味着后续备份会相当快速,因为它们只传输很小的数据量。
注意事项
备份原理:这个会拿到你集群里当前的状态和数据然后保存到一个共享仓库里,这个备份过程是”智能”的
随着不时的对数据进行快照,备份也在增量的添加和删除,后续备份会相当快速,因为数据量会很小
- 在进行本地备份时使用 —type 需要备份索引和数据(mapping,data)
- 在将数据备份到另外一台 ES 节点时需要比本地备份多备份一种数据类型(analyzer,mapping,data,template)
| Elasticsearch | MySQL | |
|---|---|---|
| 索引 Index | 表 | |
| 文档 Document | 行 | |
| 字段 Field | 字段 | |
| 映射 Mapping | 表结构 | >) |
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/docs-reindex.html
http://dbaselife.com/project-16/doc-882/
- ES 的底层使用了 Lucene, ES 快照实际上是对 Lucene 快照文件的一次保存
- Lucene 快照包含了当前时间点上与需要快照的索引相关的全部文件。
- Lucene 的索引是由多个分段文件组成的,且分段文件是不能被修改的,只会新增和删除。
- 只有两种情况下会产生新的分段文件:1、新增、修改、删除索引内的数据 2、将已存在的分段文件合并
- 快照删除时仅删除没有被任何快照引用的文件
3.快照过程
首次快照示意图,快照名称记为:快照 A
与快照 A 关联的文件列表为:1、2、3
然后我们对ES中的数据做了一些修改,导致Lucene文件发生了一些变化。由于Lucene索引分段文件的特性,只会新增和删除而不会修改,因此此时的Lucene中文件可能如下
然后进行第二次快照,快照名称记为:快照 B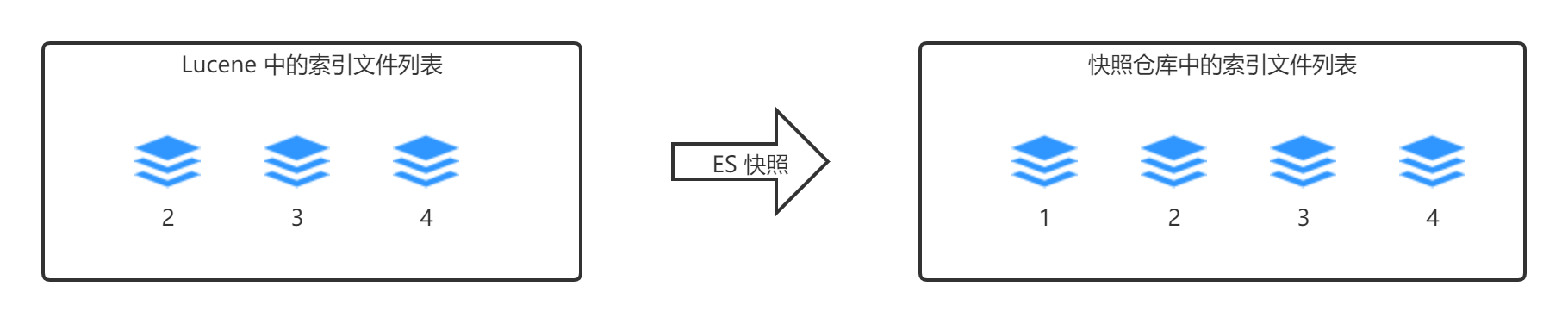
与快照 B 关联的文件列表为:2、3、4
然后删除快照 A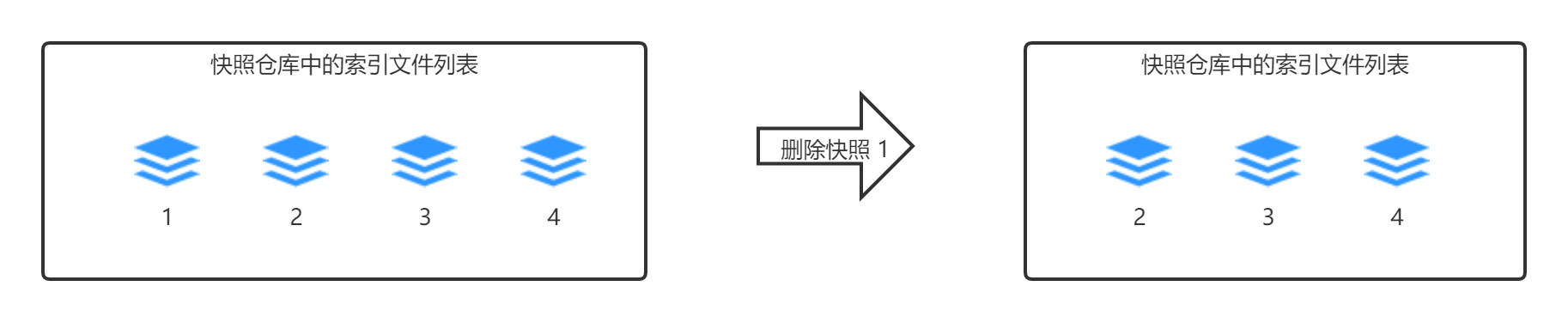
- 与快照 A 关联的文件是:1、2、3
- 与快照 B 关联的文件是:2、3、4
- 所以,只有文件 1 可以被删除
4.疑问解答
Q:删除历史快照会对新的快照造成影响吗?
A:不会的,以上面的流程为例,只会清理不被任何快照关联的文件。而每个快照关联的文件列表都能还原当时的全量数据。
Q:如果每次保存的都是差异,那我的快照数据量是不是会越来越大?
A:如果定期清理历史的快照,那么快照的数据量是不会越来越大的。虽然每次都保存的是差异,但这个差异并不是绝对的新增数据,而是对历史数据做了修改后的一个局部全量数据。也就是说,新文件和旧文件之间是有重叠数据的,所以清理历史文件即可。
Q:恢复完整数据的时候要如何恢复?需要从第一个快照开始一个一个恢复吗?
A:不需要,只需恢复指定时间点的快照即可,因为每个快照都保留了那个时间点的全量数据。
参考文档: - 《ELASTICSEARCH 源码解析与优化实战》样章-第 13 章 Snapshot 模块分析
- 备份你的集群-ES官方文档
- 备份你的集群 | Elasticsearch: 权威指南 | Elastic
准备工作
集群信息
1
2
3
4
5
6
7
8#查看健康状态
http://127.0.0.1:9200/_cat/health?v
#查看节点信息
http://127.0.0.1:9200/_cat/nodes?v
#查看分片信息
http://127.0.0.1:9200/_cat/shards?v
#查看索引信息
http://127.0.0.1:9200/_cat/indices?v创建仓库
备份开始之前,需要创建一个保存数据的仓库;类型可以是: - 共享文件系统,比如 NAS
- Amazon S3
- HDFS (Hadoop 分布式文件系统)
- Azure Cloud
创建共享目录并挂载,集群所有节点均需要操作1
2
3
4
5mkdir -p /app/data/es_backups
mount -t nfs -o vers=3 192.168.10.17:/app/data/es_backups /app/data/es_backups
#配置文件添加如下字段,指定仓库地址
echo 'path.repo: ["/app/data/es_backups"]' >> /app/service/elasticsearch/elasticsearch.yml
#然后重启服务
注册仓库
集群任一节点操作即可1
2
3
4
5
6
7curl -H "Content-Type: application/json" -X PUT 'http://127.0.0.1:9200/_snapshot/es_backups' -d'
{
"type": "fs",
"settings": {
"location": "/app/data/es_backups"
}
}'
一个仓库可以拥有同一个集群的多个快照,快照名字是唯一标识,直接浏览器访问查看1
http://192.168.10.24:9200/_snapshot/es_backups
仓库限流设置:
- max_snapshot_bytes_per_sec:快照数据保存到仓库时,默认是每秒 20mb
- max_restore_bytes_per_sec:从仓库恢复数据时,默认是每秒 20mb
- compress:是否压缩,默认为 true
- chunk_size:快照过程中,大文件会被分解成块,指定块的大小:1GB、500MB、5KB、500B,默认不受限制
- readonly:让库只读,默认为 false
1
2
3
4
5
6
7
8
9
10curl -H "Content-Type: application/json" -X POST 'http://127.0.0.1:9200/_snapshot/es_backups' -d '
{
"type": "fs",
"settings": {
"location": "/app/data/es_backups",
"max_snapshot_bytes_per_sec" : "50mb",
"max_restore_bytes_per_sec" : "50mb",
"compress":true
}
}'备份还原
创建快照
数据量大的时候执行命令后会在后台运行,使用 wait_for_completion 参数会等待完成返回结果1
curl -X PUT 'http://127.0.0.1:9200/_snapshot/es_backups/20230105?wait_for_completion=true'

默认备份所有索引,也可以指定索引然后查看快照信息1
2
3
4curl -H "Content-Type: application/json" -X POST 'http://127.0.0.1:9200/_snapshot/es_backups/20230105' -d '
{
"indices": "chat-single-wwdda403ba68de53fc,chat-group-wwdda403ba68de53fc"
}'
1 | #查看仓库存储的所有快照 |
恢复快照
1 | curl -X POST 'http://127.0.0.1:9200/_snapshot/es_backups/20230105/_restore?wait_for_completion=true' |
默认会恢复快照里所有的索引,跟创建快照一样,也指定进行恢复的索引,并且在恢复时重命名1
2
3
4
5
6curl -H "Content-Type: application/json" -X POST 'http://127.0.0.1:9200/_snapshot/es_backups/20230105/_restore?wait_for_completion=true' -d '
{
"indices": "chat-single-wwdda403ba68de53fc,chat-group-wwdda403ba68de53fc",
"rename_pattern": "chat-(.+)",
"rename_replacement": "restored-chat-$1"
}'
数据量大时,查看恢复状态1
http://127.0.0.1:9200/_snapshot/es_backups/restored-chat-single-wwdda403ba68de53fc/_recovery
删除快照
1 | curl -X DELETE "http://127.0.0.1:9200/_snapshot/es_backups/20230105" |
注销仓库1
curl -X DELETE "http://127.0.0.1:9200/_snapshot/es_backups"
备份方案
方案说明
第一个快照会是一个数据的完整拷贝,但是所有后续的快照会保留的是已存快照和新数据之间的差异。随着你不时的对数据进行快照,备份也在增量的添加和删除。
Elasticsearch 中可能会有很多个 index,为了在恢复的时候尽可能的方便,单 index 生成快照
方案脚本
1 |
|
 微信
微信 支付宝
支付宝



